Machine Learning in Healthcare: Part 1 - Learn the Basics
 Bob HoytThis is the first in a series of articles on the use of machine learning in healthcare by Bob Hoyt MD FACP. Parts 2 and 3 can be read here and here.
Bob HoytThis is the first in a series of articles on the use of machine learning in healthcare by Bob Hoyt MD FACP. Parts 2 and 3 can be read here and here.
This article is the first in a three-part series that will discuss how machine learning impacts healthcare. The first article will be an overview defining machine learning and explaining how it fits into the larger fields of data science and artificial intelligence. The second article will discuss machine learning tools available to the average healthcare worker. The third article will use a common open source machine learning software application to analyze a healthcare spreadsheet.
Part 1 was written to help healthcare workers understand the fundamentals of machine learning and to make them aware that there are simple and affordable programs available that do not require programming skills or mathematics background. To the average healthcare worker machine learning (ML) is confusing and controversial. The first step is to understand how ML fits in the overall scheme of data science and artificial intelligence. The second step would be to understand how it compares to traditional statistics and programming languages such as R and Python. The third step would be to understand why machine learning is a cornerstone of predictive modeling.
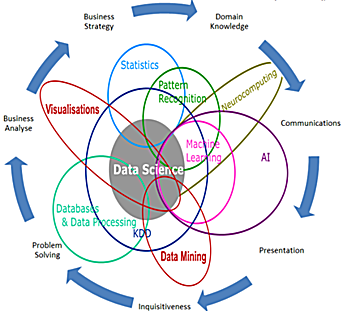
Data science is a relatively new field that processes data from start to finish, with emphasis on analysis. Many information science fields fall under this umbrella. The Venn diagram below by Brendan Tierney shows data science at the center of the diagram with multiple overlapping fields. Machine learning is generally included under the field of artificial intelligence which is a subfield of computer science. Because this is an evolving field there are many different interpretations of how the fields intersect and overlap.
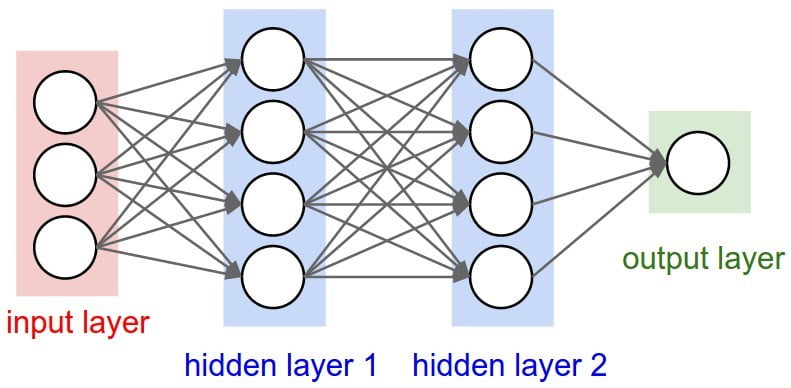
Artificial intelligence (AI) has been around for more than six decades but has matured greatly in the past decade and is now a well-recognized player in the medical field and is associated with its own journal. AI relies heavily on artificial neural networks (ANNs) which are analogous to the human neuron. In addition to an input and output layer, there are many hidden layers. Deep learning uses ANNs but involves more layers and more complex than simple neural networks. The figure below shows the architecture of the different layers.
ANNs are extremely important algorithms but suffer from complexity, unlike simple decision trees that are easy to understand and visualize.
AI has been used extensively in radiology as computer-aided diagnosis. For example, one article published in 2017 discussed how deep learning networks were used to detect tuberculosis with almost 100% accuracy. Similarly, AI can be used to augment the interpretation of the pathologist on biopsy specimens. Artificial intelligence can be used to interpret retinal diabetic retinopathy on captured retinal images and AI can also help interpret EKGs and EEGs. An area of great interest is in clinical decision support. AI helps to predict outcomes from massive structured and unstructured data in the electronic health record. In an article published in 2017, a variety of machine learning algorithms analyzed EHR data and it was compared to an established cardiovascular risk prediction calculation. The ML algorithms outperformed the established American College of Cardiology guidelines to predict the risk of cardiovascular disease.
Two examples of recent AI medical projects include Deep Patient and DeepVariant. Deep Patient is an Icahn School of Medicine project that mines structured and unstructured EHR data for prediction. Published studies indicate that deep learning outperformed traditional prediction methodologies for diseases, such as diabetes, schizophrenia, and cancer. DeepVariant is an open-source platform released by the Google Brain team that uses deep learning to detect genetic variants.
As noted, machine learning is included in artificial intelligence and it includes neural networks as well as multiple other algorithms. A helpful definition of ML is “Machine learning is a method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention.” So, machine learning uses algorithms to create predictive models based on training data and validated with test data.
Machine learning is most commonly used to build predictive models (predictive analytics). Once appropriate data are chosen, explored and “cleansed” an analysis is undertaken using a variety of algorithms. The outcome might be binary, such as patient developed recurrent breast cancer or not and the attributes or factors influencing the outcome might be tumor size, axillary node involvement, age, menopausal status, etc.
 You might create several models using different factors. Using multiple outcome validation measures such as the area under the ROC curve (AUC), precision, sensitivity, etc. the best algorithm is chosen that created the best performing model. In addition, most algorithms can be fine-tuned for better performance. The model is developed using training data, but the ultimate test would be testing the model on brand-new data to see if it still performs as well as it did on the training data. A common procedure would be to train the model on 70% of the data and test it on the remaining 30%. The figure below outlines the modeling process.
You might create several models using different factors. Using multiple outcome validation measures such as the area under the ROC curve (AUC), precision, sensitivity, etc. the best algorithm is chosen that created the best performing model. In addition, most algorithms can be fine-tuned for better performance. The model is developed using training data, but the ultimate test would be testing the model on brand-new data to see if it still performs as well as it did on the training data. A common procedure would be to train the model on 70% of the data and test it on the remaining 30%. The figure below outlines the modeling process.
There is a tendency to think of machine learning in terms of artificial intelligence and deep learning and how they relate to “big data.” The reality is that machine learning has earned a place in routine predictive modeling of far smaller datasets; for example, predicting 1-year mortality from electronic health record data.
A common ML scenario might be to determine factors that predict readmission for heart failure. You have located a dataset that has multiple interesting risk factors and you have explored the data and deleted any patients who do not have the outcome of readmitted, yes or no. You train multiple algorithms on the training data, such as logistic regression, Naive Bayes, neural networks and random forest. You determine that the best results overall are with random forest. You create several models to see if factors such as age, zip code, gender, and insurance status are strong or weak predictors. You test the model with new test data and determine that the AUC is good at .85. You deploy and monitor the model.
Data scientists can also use statistical packages, such as SPSS and SAS and the programming languages R and Python, in addition to machine learning (ML) to model and analyze data. How is machine learning different from traditional statistics? Clearly, statistics are based on mathematics and probability. Prior to the computer age, statistics were calculated by hand, an arduous task, with the potential for error. Furthermore, with robust computing power machine learning can include deep learning and pattern recognition which are not part of traditional statistics. Machine learning can be more forgiving of missing data and handle non-linear models. We are seeing some convergence between the two fields. For example, it is common for both fields to embrace ML and the programming languages for predictive modeling. R programming is very common in the biomedical sciences and Python is more common among computer scientists. Programming languages, such as R and Python have many merits but are associated with a very steep learning curve.
In Part 2 we will discuss how the multiple choices available for the average healthcare worker to deploy machine learning in healthcare.
- Tags:
- AI medical projects
- artificial intelligence (AI)
- artificial neural networks (ANNs)
- Bob Hoyt
- Brendan Tierney
- Clinical Decision Support (CDS)
- data science
- deep learning networks
- Deep Patient
- DeepVariant
- Electronic Health Record (EHR)
- genetic variants
- Google Brain
- Health IT
- healthcare
- Icahn School of Medicine
- machine learning (ML)
- machine learning algorithms
- machine learning software application
- machine learning tools
- open health
- open source machine learning software
- open source software (OSS)
- predictive analytics
- predictive modeling
- programming languages
- Python
- R Language
- statistics
- structured EHR data
- unstructured data
- unstructured EHR data
- Login to post comments